从浏览器输入网址到网页展示的全过程
1、在浏览器输入要的网址
2、浏览器查找域名的IP地址
- 浏览器缓存 - 浏览器会缓存DNS记录一段时间,不同的浏览器的缓存时间不一样(Chrome的过期时间是1分钟)。
- 路由缓存 - 接着前面的查询请求发向路由器,它一般会有自己的DNS缓存。
- ISP DNS缓存 - 接下来要check的就是ISP缓存DNS的服务器。在这一般都能找到相应的换粗记录。
- 递归搜索 - 你的ISP的DNS服务器从跟域名服务器开始进行递归搜索, 从.com顶级域名服务器到百度的域名服务器。一般DNS服务器的缓存中会有.com域名服务器中的域名,所以顶级服务器的匹配过程不是那么必要了。
3、浏览器与服务器建立链接
在请求之前,需要浏览器与服务器建立连接(TCP或者UDP)
- 与服务器建立连接时TCP属于安全的连接,需要三次握手。
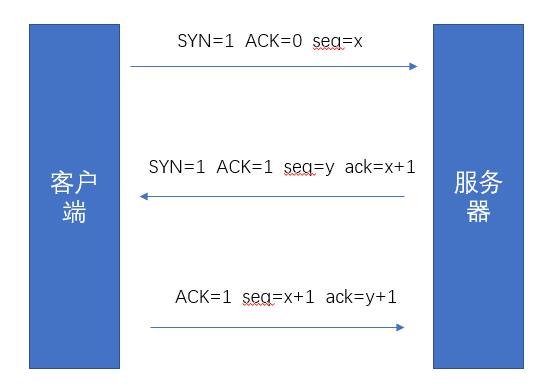
SYN:代表请求创建连接,所以在三次握手中前两次要SYN=1,表示这两次用于建立连接。
FIN:表示请求关闭连接,在四次分手时,我们发现FIN发了两遍。这是因为TCP的连接是双向的,所以一次FIN只能关闭一个方向。
ACK:代表确认接受,从上面可以发现,不管是三次握手还是四次分手,在回应的时候都会加上ACK=1,表示消息接收到了,并且在建立连接以后的发送数据时,都需加上ACK=1,来表示数据接收成功。
seq:序列号,什么意思呢?当发送一个数据时,数据是被拆成多个数据包来发送,序列号就是对每个数据包进行编号,这样接受方才能对数据包进行再次拼接。
- 与服务器建立连接时TCP属于安全的连接,需要三次握手。
- 与服务器响应软件建立管道连接(socket)
4、浏览器给WEB服务器发送HTTP请求
百度主页为动态页面,打开后在浏览器缓存中很快甚至马上就会国旗,毫无疑问他们不能从之读取。所以,浏览器将把以下请求发送给百度所在的服务器:
1
2
3
4
5
6
7
8
9
10Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cache-Control: no-cache
Connection: keep-alive
Cookie: BAIDUID=DB950B3D3996ECE570E2C2B148A24BF7:FG=1; BIDUPSID=DB950B3D3996ECE570E2C2B148A24BF7; PSTM=1552621892; delPer=0; BD_HOME=0; H_PS_PSSID=1426_21094_28558_28608_28585_28604_22159; BD_UPN=123253
Host: www.baidu.com
Pragma: no-cache
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36解析请求含义
- Accept 客户端希望接受的数据类型
- Accept-Encoding 支持gzip, deflate, br类型
- Accept-Language 允许客户端声明它可以理解的自然语言
Cache-Control - HTTP 1.1(Pragma - HTTP 1.0):
- no-cache — 不要读取缓存中的文件,要求向WEB服务器重新请求
- no-store — 请求和响应都禁止被缓存
- max-age: — 表示当访问此网页后的max-age秒内再次访问不会去服务器请求,其功能与Expires类似,只是Expires是根据某个特定日期值做比较。一但缓存者自身的时间不准确.则结果可能就是错误的,而max-age,显然无此问题.。Max-age的优先级也是高于Expires的。
- max-stale — 允许读取过期时间必须小于max-stale 值的缓存对象。
min-fresh — 接受其max-age生命期大于其当前时间 跟 min-fresh 值之和的缓存对象
only-if-cached — 告知缓存者,我希望内容来自缓存,我并不关心被缓存响应,是否是新鲜的.
no-transform — 告知代理,不要更改媒体类型,比如jpg,被你改成png.
- Connection头要求服务器为了后边的请求不要关闭TCP连接。
- Cookie 存储登陆用户名
- User-Agent 浏览器标示
5、服务器处理请求(nginx+php-fpm)
6、服务器返回一个HTML响应
1 | Cache-Control: private |
7、浏览器开始显示HTML
- 在浏览器没有完整接受全部HTML文档时,它就已经开始显示这个页面了
8、加载网站文件
- 解析HTML文档、构建DOM树、下载资源、构造CSSOM树、执行JS脚本(没有严格的先后执行顺序)
- 构建DOM树:
- Tokenizing:根据HTML规范将字符流解析为标记
- Lexing:词法分析将标记转换为对象并定义属性和规则
- DOM construction:根据HTML标记关系将对象组成DOM树
- 解析过程中遇到图片、样式表、JS文件,启动下载
- 构建CSSOM树:
- Tokenizing:字符流转换为标记流
- Node:根据标记创建节点
- CSSOM:节点创建CSSOM树
- 根据DOM树和CSSOM树构建渲染树:
- 从DOM树的根节点遍历所有可见节点,不可见节点包括:1)script,meta这样本身不可见的标签。2)被css隐藏的节点,如display: none
- 对每一个可见节点,找到恰当的CSSOM规则并应用
- 发布可视节点的内容和计算样式
- JS解析:
- 浏览器创建Document对象并解析HTML,将解析到的元素和文本节点添加到文档中,此时document.readystate为loading
- HTML解析器遇到没有async和defer的script时,将他们添加到文档中,然后执行行内或外部脚本。这些脚本会同步执行,并且在脚本下载和执行时解析器会暂停。这样就可以用document.write()把文本插入到输入流中。同步脚本经常简单定义函数和注册事件处理程序,他们可以遍历和操作script和他们之前的文档内容
- 当解析器遇到设置了async属性的script时,开始下载脚本并继续解析文档。脚本会在它下载完成后尽快执行,但是解析器不会停下来等它下载。异步脚本禁止使用document.write(),它们可以访问自己script和之前的文档元素
- 当文档完成解析,document.readState变成interactive
- 所有defer脚本会按照在文档出现的顺序执行,延迟脚本能访问完整文档树,禁止使用document.write()
- 浏览器在Document对象上触发DOMContentLoaded事件
- 此时文档完全解析完成,浏览器可能还在等待如图片等内容加载,等这些内容完成载入并且所有异步脚本完成载入和执行,document.readState变为complete,window触发load事件
- 显示页面(HTML解析过程中会逐步显示页面)
- 构建DOM树: